AI 绘画的技术本质:从概率预测到视觉工程
AI 绘画通过深度学习模型将文字转化为视觉图像。其技术逻辑是利用海量数据训练的潜空间映射,在像素层面模拟人类的审美与构图。到 2026 年 3 月,该技术已从简单的“图片生成”转向精准的“视觉工程”,核心争议点已从“能否画画”转移到“如何通过参数控制将其转化为生产力工具”。
AI 绘画的本质是概率预测而非意识创作
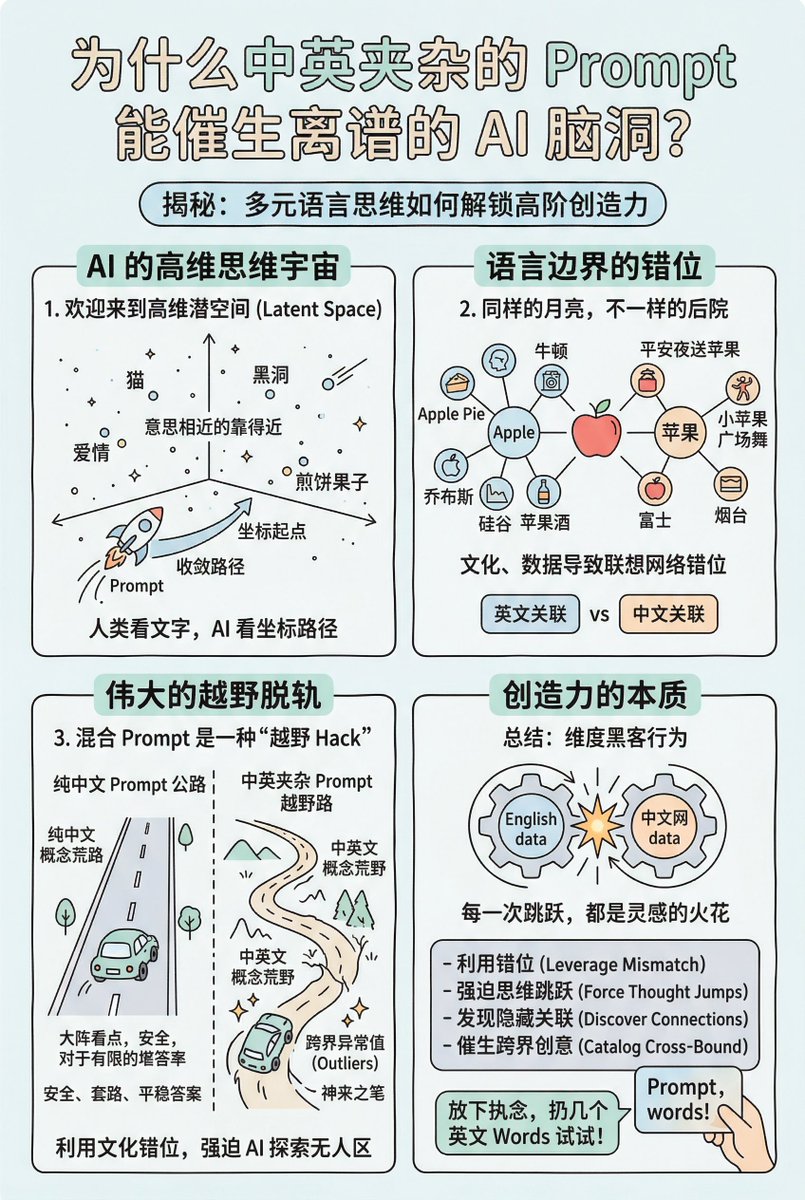
输入提示词后,模型在极高维度的数学空间中寻找与词汇关联度最高的像素分布。由于其基于统计学的机制,AI 处理标准化视觉语言时极其高效,但在处理具有强个人特质的艺术表达时,容易出现“平均化”倾向,导致作品缺乏独特的灵气。
目前主流 AI 绘画基于扩散模型(Diffusion Models)。其过程分为前向扩散(向图像添加随机噪声直至变为“雪花点”)和反向去噪(学习剔除噪声还原图像)。用户输入提示词,AI 便在噪声图中引导特征迭代,最终生成目标图像。
潜空间(Latent Space)是降低计算量的关键。模型不在巨大的像素矩阵中操作,而是在压缩后的低维空间处理。这意味着 AI 识别的不是具体物体,而是潜空间中的坐标点。所谓的“提示词工程”,本质上是在潜空间中通过文字寻找精准坐标。
商业级产出的结构化实操流程
要实现商业级产出,必须建立结构化流程,不能依赖单词堆砌。以 Stable Diffusion 及其 2026 年版本为例,操作路径如下:
配置显存不低于 24GB 的 GPU 以支持高分辨率原生生成,安装 WebUI 或 ComfyUI 并配置 Python 虚拟环境。写实风格选择 Realistic Vision 系列,动漫风格选择专用模型。优先使用 .safetensors 格式确保安全性。
其次是构建结构化提示词

一个精准的指令需包含四个维度:主体描述(具体名词)、环境背景(定义光影)、风格定义(指定镜头语言)以及负面提示词(排除畸形肢体)。
[主体]: A woman with pale blue eyes, wearing a 19th-century Victorian lace gown
[背景]: Dusk London street, wet pavement with neon reflections
[风格]: Hasselblad medium format, f/2.8 aperture, cinematic lighting
[负面]: (deformed limbs, low resolution, blurry, extra fingers)
在参数配置上,采样步数建议设在 20-30 步,过高会导致过度锐化,过低则细节缺失。采样器推荐 DPM++ 2M Karras 或 Euler a。
ControlNet 是区分业余与专业的关键
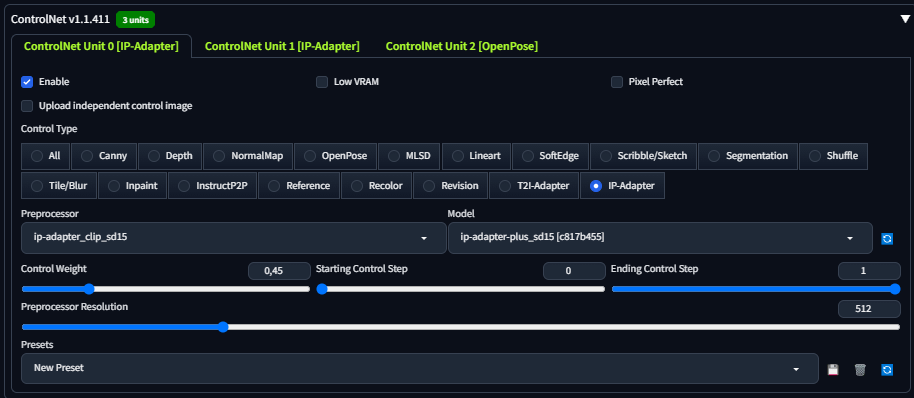
它允许用户通过参考图引导生成,而非仅靠文字。在插件面板上传姿势图(Pose map)或线稿图(Canny edge),选择 openpose 或 canny 预处理器。将控制权重设为 1.0 时,AI 严格遵循参考图;设为 0.6-0.8 则保留一定的创作空间。
开启 Hires. fix,选择 R-ESRGAN 4x+ 算法,重绘幅度控制在 0.3-0.5。对于残缺部位,使用 Inpaint 模式涂抹,将重绘幅度调高至 0.6 并输入具体修复词(如 "perfectly detailed human hand")进行像素重构。
工具生态与应用边界
目前的工具分为三类
针对不同的商业需求,应选择不同的工具矩阵:
| 工具 | 核心优势 | 适用场景 | 控制力 |
|---|---|---|---|
| Midjourney | 审美极高,出图迅速 | 概念草图、氛围图 | 较低 |
| Stable Diffusion | 开源生态,插件丰富 | 工业设计、商业交付 | 极高 |
| Artflow.ai | 低门槛,功能特定 | 快速配图、非专业用户 | 中等 |
AI 绘画的局限性与反思
AI 绘画并非万能。在需要“绝对一致性”的连环画中,即便使用 Lora 固定角色,极端角度下仍会出现面相漂移。在精密机械剖面图等技术图纸中,AI 追求的是视觉相似而非逻辑正确,内部齿轮啮合等物理结构常出现错误。
在先锋艺术领域,AI 倾向于将图像“修正”为符合大众审美的标准模样。而艺术的价值往往在于对概率的“反叛”,例如故意扭曲色彩以表达压抑,这种个人主义表达目前仍是 AI 的弱项。
如何解决 AI 生成图像中的肢体畸形问题?
建议采用 ControlNet 的 OpenPose 骨架引导,或者在生成后使用 Inpaint(局部重绘)功能,配合高重绘幅度(0.6+)和具体的修正提示词进行像素级重构。
AI 绘画是否会完全取代原画师?
不会,但会改变工作流。AI 擅长处理概率性的视觉生成,而原画师提供逻辑正确性、情感深度和最终的精度修正。未来的核心竞争力将从“绘画技巧”转向“审美把控”与“工作流集成能力”。
共生时代:构建闭环工作流
版权争议的核心在于模型训练阶段未经许可抓取作品。但到 2026 年,行业正转向共生关系。艺术家通过训练个人私有 Lora 模型,将 AI 变为数字助手。在这种模式下,在千万种可能性中筛选出最具灵性的瞬间,本身即是一种创作行为。
人类主导(Midjourney 发散构思) $\rightarrow$ AI 辅助(Stable Diffusion 锁定结构并微调细节) $\rightarrow$ 人类修正(Photoshop 进行光影精修和逻辑修正)。
与其死磕提示词单词,不如学习构图法、色彩理论和光影物理学。当工具门槛降至零,决定产出质量的是审美上限。尝试用 AI 还原一个你心中深刻但难以言说的场景,在重绘与修正中寻找技术与直觉的平衡点。